另一个视角的英伟达 — 看似无敌,裂缝已经显形。
算力是确定性强需求,且指标极度明确。与苹果、特斯拉这类 C 端产品不同 — C 端决策因素多样、品牌 / 情绪 / 生态黏性都会让客户「非理性」 — 而 B 端大客户极度理性冷血:只要有更优替代或竞争者,他们会毫不犹豫切换,至少也会主动培养第二供应商以维护议价权。英伟达的垄断不是金刚不坏:它只是入场够早、规模够大、生态拉得够远。这是一条清晰的赛道,挑战者必然层出不穷,而且一旦放慢就会被赶上。本文围绕四个问题:① 为什么挑战者突然涌现 → ② 在哪里发生 → ③ 还有什么会加速这个过程 → ④ 什么时候发生、怎么观察。
§01 · 另一个视角 — why NVDA isn’t invincible

图片:Wikimedia Commons / NVIDIA · Public Domain。
英伟达的护城河是真实的 — CUDA、NVLink、HBM 锁单、CoWoS 产能、25 年生态积累 — 但所有 B 端故事的真实底层都是客户的理性。这是它和苹果、特斯拉最大的区别。Apple 一年 2 亿台 iPhone 卖给消费者,情绪和品牌占决策的一大半;Tesla 同理。但卖给 OpenAI / Anthropic / 微软 / 谷歌 / Meta / 字节的 GPU,买方都是世界上最理性冷血的工程团队 — 他们看的是 token/美元、token/瓦特、单次训练总成本,不看 logo,不讲品牌。
这意味着 NVIDIA 的垄断有一个内置的不稳定性:一旦慢下来,大客户会立刻培养第二供应商。看看现在已经发生的事 — Google 自研 TPU(且向外输出)、Amazon 自研 Trainium、Microsoft 自研 Maia、Meta 自研 MTIA、OpenAI 投 $20B 给 Cerebras + 与博通合自研推理芯片。每一家都在主动「养二供」。这不是阴谋论,是 B 端采购的 ABC。
| 指标 | 数值 | 备注 |
|---|---|---|
| FY26 数据中心收入 | $215.9B | +89% YoY · Q4 $62.3B · 占总收入 ~89% · 四家 CSP 合计 61% 季度营收(NVIDIA Newsroom) |
| 非 GAAP 毛利率 | ~75% | Q4 75% · 指引中段 75% · B200 单卡毛利率 ~84%(售价 $35–40K · 制造成本 ~$6.4K) |
| AI 加速器市占 | 80–90% | 不同口径差异大 · 2024 峰值 87% · 2026 预期 ~75% |
| 单次训练成本 | $50M–$500M | 超大模型量级 · 错误成本极高 → 没人愿意拿不成熟硬件冒险 · 训练堡垒成因 |
英伟达的垄断不是金刚不坏:护城河是真实的,但只是「入场早 + 规模大 + 生态远」三件事的总和,不是结构性不可逾越的。一旦放慢,后面的挑战者会蜂拥而上;客户的理性会反向加速这个过程。
— 这里要回答的不是「会不会」,是「什么时候」与「怎么观察」
§02 · 架构收敛 — why challengers suddenly appeared
2012 · CNN 起点
2015 · 残差连接
2018 · Encoder-only
1997 · RNN / 序列
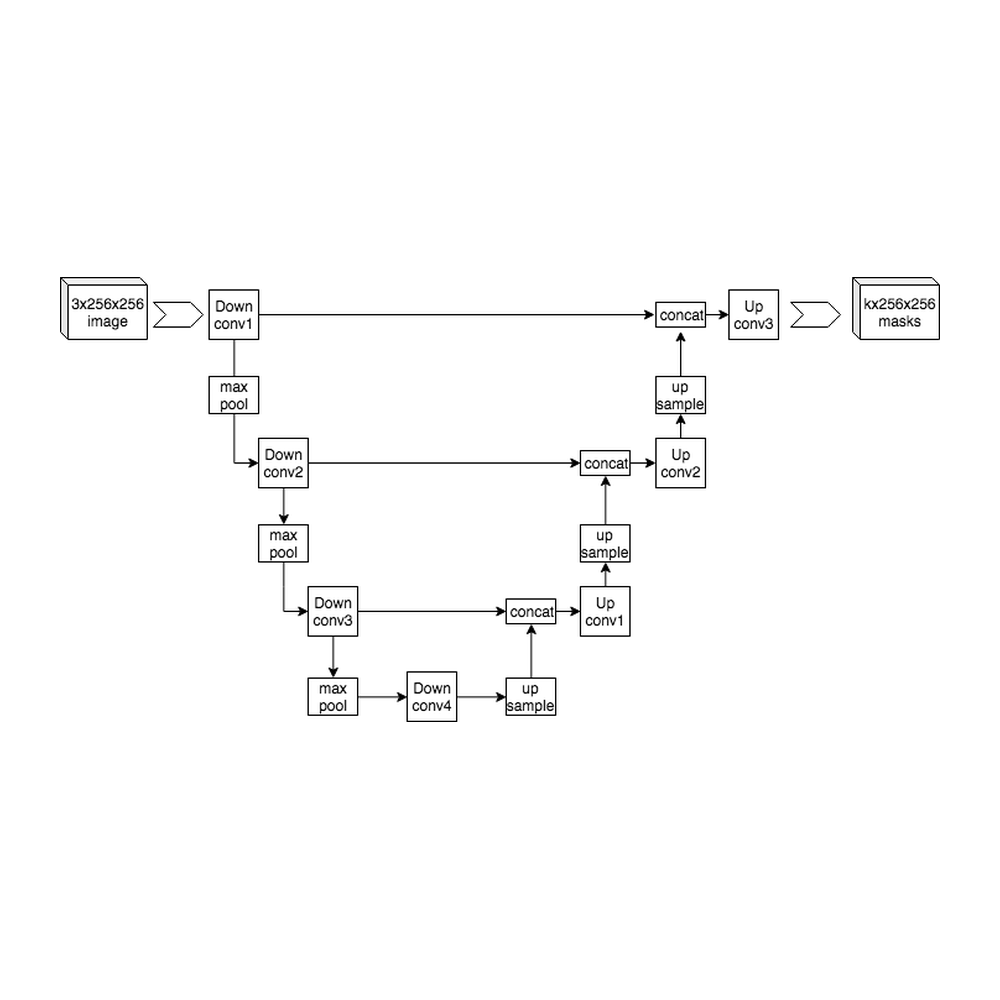
2015 · 图像分割
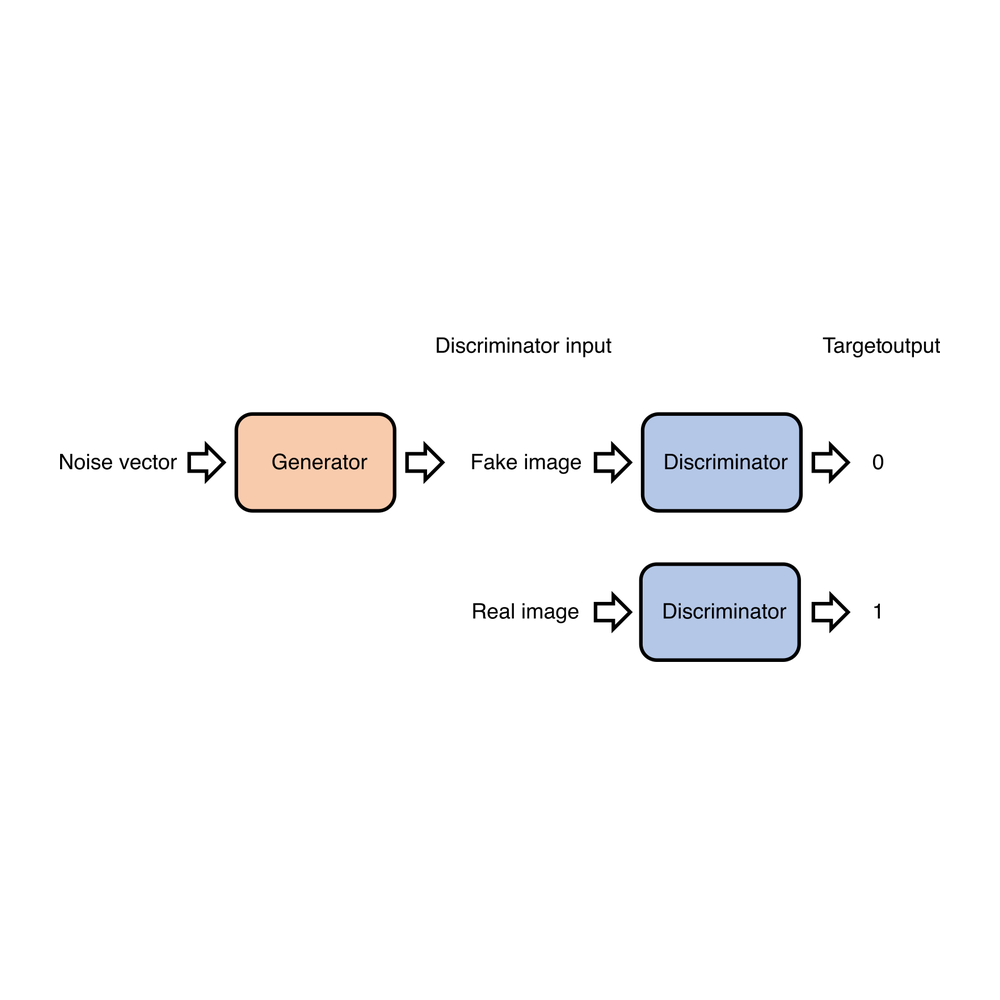
2014 · 生成对抗
变体只剩注意力分组:MHA → MQA → GQA → MLA
架构图来自 Wikimedia Commons(AlexNet · ResNet 残差块 · BERT · LSTM · U-Net · GAN · Full GPT Architecture),CC BY-SA 4.0 / CC0 Public Domain。
挑战者并不是凭空冒出来的,背后有一个常被忽略的结构性变化:模型架构正在收敛。CNN 时代是百花齐放 — AlexNet / VGG / ResNet / Inception / MobileNet / EfficientNet — 每个任务都有自己的「最佳架构」,硬件不知道该为哪种优化,通用 GPU 大获全胜。Transformer 时代正好相反:从 2017 年原始论文到 2026 年的前沿模型,骨架几乎没变过 — Pre-LayerNorm、RoPE、RMSNorm、SwiGLU、Residual、KV Cache 都是几年前的老技术。
当下的「创新」基本只剩注意力分组的几个变体(MHA → MQA → GQA → MLA),GQA 已经是开源大模型的事实默认值;Mamba / SSM 等挑战者最终都以「混合架构」形式出现而非替代 Transformer — 一篇 NeurIPS 2025 的论文甚至证明了 Mamba 和 Transformer 在计算复杂度上属于同一类、本质等价。这是 ML 历史上前所未有的稳定性。它的意义和当年 x86 的胜出一样 — 架构收敛之后,硬件优化的目标第一次变得确定。
收敛释放出的硬件设计自由度
- 算子可以彻底固化。 从几百个砍到几个核心算子(MatMul、Softmax、RoPE、LayerNorm)就够了,所有非必需电路都可以砍掉。GPU 通用性的代价是大量晶体管被浪费在不会被 LLM 调用的路径上。
- 数据流可以编译期排好。 Transformer 计算图静态规整,不需要 GPU 的复杂动态调度 — GPU 大量晶体管浪费在 warp scheduler、memory coalescing 这类适配「未知工作负载」的电路上。
- 内存层次可以量身定做。 参数大小、KV Cache 大小、激活值大小都预先已知。挑战者可以为「7B 模型 + 32K 上下文」直接设计 SRAM/HBM/DRAM 层次,而不是像 GPU 那样为「任意工作负载」预留缓冲。
- 数值精度可以激进。 int4 / int8 已是推理常态,FP4 / FP6 是研究热点。GPU 还得保留 FP32 / FP64 的电路服务科学计算市场 — 这部分对 LLM 完全是冗余。
- 极致:权重直接烧进硅片。 Taalas 的路线把「架构收敛」推到逻辑终点 — 把 Llama 3.1 8B 的 32 层权重作为物理晶体管直接 etch 到芯片上。芯片就是模型本身,不能改,但 perf/watt 宣称比 GPU 集群好 1000 倍。详见 §03。
护城河没被攻破,而是被绕开了
CUDA 厚度优势的前提是「需要支持几百个算子」 — 模型收敛之后这个前提消失了。
类比:以前 Office 的护城河是几千个功能组件,结果今天大家用 Notion 写文档,那几千个功能用不到 50 个 — 护城河没被攻破,是被绕开了。
这就是为什么 2024–2026 年突然涌出这么多 AI 芯片初创:不是资本忽然变多,是设计目标第一次稳定下来,赌注的胜率被根本性提高了。再叠加 Claude Code / Codex 这类 AI 编程工具普及之后,软件迁移的成本结构正在被重写 — CUDA 的护城河正在双重侵蚀。
§03 · 训推分裂 — two markets, two logics

图片:Wikimedia Commons / Google · CC BY 4.0。
把训练和推理混在一起看,会严重误判英伟达的真实位置。算力分配正在剧烈翻转:2023 年训练:推理 ≈ 2:1,2025 年 1:1,2026 年 1:2,2029 年会接近 1:4。Lenovo 高管 CES 2026 直说「未来训练 20%、推理 80%」;Jensen 自己也承认推理市场最终会比训练市场大「约十亿倍」。单个 AI 系统的生命周期里,推理占总成本 80–90%,训练只占 10–20%。
这意味着:英伟达真正赚大钱的市场(训练)正在变成相对小的市场;真正巨大的市场(推理)是它护城河最薄的地方。
训练 vs 推理 · 算力占比的剪刀差
2025 年是分水岭 — 推理首次超过训练。到 2029 年训练仅剩 ~20%,推理 ~80%。NVIDIA 在训练市场的统治力短期无解,但在推理市场每一条工作负载特征都对它不利。
训练市场:堡垒,英伟达短期无解
- 算力极度集中。 单次训练几万张卡协同,对 NVLink / InfiniBand 要求极高;非 GPU 路线缺这一层完整生态。
- 客户极度集中。 全球做前沿预训练的玩家不到 10 家 — OpenAI、Anthropic、xAI、Google、Meta、Microsoft、字节、Mistral、DeepSeek、Cohere — 决策路径短、个个都和 Jensen 直接通话。
- 错误成本极高。 一次训练几亿美元、半年时间。没人愿意拿不成熟硬件冒险 — 「nobody got fired for buying NVIDIA」是 2026 版的「nobody got fired for buying IBM」。
- 软件栈最重。 CUDA + NCCL + cuDNN + Megatron + DeepSpeed + 各种 fused kernel — 整套迁移成本巨大。Anthropic 把训练负载迁到 TPU 用了一年多。
- 模型架构在训练侧仍有变化。 MoE、长上下文、test-time scaling、稀疏激活、混合精度训练 — 训练侧还需要硬件灵活性,这是 GPU 通用性最后的舒适区。
- 结论。 训练市场 NVIDIA 2028 年大概率仍能保持 80%+ 的份额。Google TPU 是唯一已经验证训练能力的对手,但只对外开放给 Anthropic + Apple AFM 训练等少数客户,不是市场化竞争。
推理市场:软肋,每一条特征都对 NVIDIA 不利
- 可以分散部署。 单卡或小集群即可,NVLink 优势完全用不上。Cerebras / Groq / 各家自研 ASIC 在这里都站得住。
- 计算模式高度规整。 同样的 attention + FFN 调用百万次,非常适合做成 ASIC。GPU 通用性在这里完全是浪费。
- 低精度足够。 int8 / int4 就能跑,FP4 实验性可用。GPU 上保留的 FP32 / FP64 电路是白白多花的硅。
- 内存墙比算力墙更重要。 这是替代架构(wafer-scale Cerebras、in-memory computing D-Matrix、近存计算 Etched / MatX)的天然优势点 — 它们都是为「内存带宽即性能」设计的,GPU 不是。
- 客户分散且敏感于成本。 看的是 token / 美元和 token / 瓦特,不是峰值算力。Google TPU 在推理上提供 4.7× 性价比、67% 更低能耗 — Anthropic、Meta、Midjourney 已经迁移部分推理负载。
- 模型已收敛。 硬件可以彻底为定型的 Transformer 优化(见 §02)。
「过去 GPU 是唯一答案的认知是英伟达最大的护城河,现在这个认知正在崩塌。」
— Cerebras 创始人 Andrew Feldman · 2026
极致路线 · Taalas:模型厂可能直接变成硬件玩家
- 技术原理 · 权重 = 物理晶体管。 Llama 3.1 的 32 层权重作为物理晶体管直接 etch 到芯片上。不需要 HBM、不需要从内存加载权重。输入向量进来,电信号直接流过物理对应每一层的晶体管,输出再流到下一层,直到生成 token。整颗芯片 = 那个模型本身,不能改。
- 性能 · 17,000 tok/s · 比 GPU 集群好 1000× perf/watt。 Llama 3.1 8B 上 17,000 tokens/秒,单个 250W 空冷卡顶一整个 GPU 集群。Taalas 用自动化设计流程,从权重到硅片的周期压缩到 2 个月,只需更换顶层金属掩膜 — 架构稳定 7–8 年没大变,折旧风险显著降低。
- 如果跑通 · 模型厂 → 硬件玩家。 OpenAI 卖 GPT-Edition 推理卡、Anthropic 卖 Claude-Edition 推理盒,绕开云厂商也绕开 NVIDIA。企业部署从「买 GPU + 下载权重 + 配 CUDA」变成「买盒子,插电」。隐私和 IP 同时解决 — 权重物理上在客户机房,提取出来等于反向工程一颗芯片。OpenAI 投 $20B 给 Cerebras 采购 + 与博通合作开发自研推理芯片,正是这个逻辑的早期信号。
挑战者格局全景(2026)
融资 / 客户 / 路径口径 · 数据来源 Fortune、CNBC、Digitimes、TrendForce(2026 Q1)。
| 类别 | 玩家 | 路径 / 优势 | 客户 / 状态 | 关键数字 |
|---|---|---|---|---|
| 大厂自研 | Google · TPU | ASIC · 训推双栈 | 内部 + Anthropic + Apple AFM 训练 | v4/v5p · 推理性价比 4.7× |
| 大厂自研 | Amazon · Trainium / Inferentia | ASIC · 主推推理 | Anthropic · AWS 内部 | Trainium2 量产爬坡 |
| 大厂自研 | Microsoft · Maia | ASIC · 自家云推理 | Azure 内部 + OpenAI 部分 | 2024 起量产 |
| 大厂自研 | Meta · MTIA | ASIC · 推荐 + LLM 推理 | Meta 内部 | MTIA v2 部署 |
| 自研 vs GPU 剪刀差 | TrendForce 2026 出货增速 | ASIC +44.6% vs GPU +16.1% | 结构性 · 非周期性 | 2027 年 ASIC 占数据中心 15%+ |
| 独立厂商 | Cerebras · WSE | 晶圆级 · in-package | OpenAI 据报采购 $20B · IPO 中 | 5 月中旬 IPO 估值 $30B+ |
| 独立厂商 | Groq · LPU | 低延迟 token-batch | 已被 NVIDIA $20B 收编 IP / 团队(2025-12) | 收编本身证明威胁 |
| 独立厂商 | D-Matrix | in-memory compute | Microsoft 支持 | 2026 拿 $5B 级融资 |
| 独立厂商 | SambaNova | reconfigurable dataflow | Intel 据报已签 term sheet 收购 | 收购中 |
| 独立厂商 | Etched / MatX / Ayar Labs | 近存 / 光互联 | 2026 各拿 $5B 级融资 | 硅光趋势 |
| 独立厂商 | Furiosa / Positron / Taalas | 韩国 + 美国新锐 · 模型烧硅 | Taalas:Llama 3.1 8B @ 17K tok/s | perf/watt 1000× |
| 地缘 · 中国 | 华为昇腾 · 阿里 PPU · 寒武纪 · 壁仞 | 出口管制催熟 | 中国 AI 芯片市场 ~$50B/yr(Jensen 估) | 2025 国产替代加速 |
| 地缘 · 欧洲 | Fractile · Axelera · Euclyd · Optalysys | 光子 / 模拟计算 | 早期 | 更长远 |
| 初创总融资 | 2026 全球 AI 芯片初创 | 资本已押「NVIDIA 不可能永远赢」 | 2026 累计融资 | $8.3B |
数据来源:Fortune (2026-01)、CNBC (2026-04-17)、Digitimes、TrendForce 2026 Q1。Cerebras 5 月中 IPO 时间为公开披露;OpenAI-Cerebras $20B 采购意向为媒体报道。NVIDIA 自己已投 $4B 做对冲(光子计算、模拟 / 物理计算)。
§04 · 政治风险 — independent variable

图片:Wikimedia Commons / Public Domain。
英伟达的政治风险被普遍低估。Jensen 在 2026-04-15 Dwarkesh Patel 的播客上反复做「表忠心」式发言、且与主持人发生争论:被问及向中国出售先进芯片的国家安全风险时,他失态地回了一句 “You’re not talking to somebody who woke up a loser”。批评者认为他在国安问题上反复回避正面回答,只强调「美国技术多卖一点是好的」,被认为过度功利。更早在 Bg2 播客上,他把「China hawk」标签称为 “a badge of shame”,被评论文章批评为「在为环球时报社论试镜」。
与苹果 · 特斯拉的本质区别
- 苹果 · 供应链敞口 · 贡献给中国。 苹果的中国敞口是制造供应链 + 部分销售 — 印度 / 越南正在分散。资金流向:中国制造 → Apple 采购 → 供应链工人受益。叙事可以解释为「贡献给中国」。苹果自带普世价值观,被国会拷问时姿态友好。
- 特斯拉 · 市场+工厂 · 工业能力贡献。 Tesla 上海工厂是中国 EV 产业链的样板,Cybertruck / Model Y 销给中国消费者。马斯克自带 MAGA 属性,顶多是民主 / 共和的内部争议,但不会有「亲共」的外部通敌性质风险。
- 英伟达 · 卖给中国 · 战略物资 · 通敌嫌疑。 NVIDIA 是**「卖给中国」**,而且卖的是被官方定义为「军用关键技术」的东西 — 这是质的区别,不是量的区别。叠加 Jensen 的华裔身份 + 反复表态被质疑「过度功利」,美国基层群众对亲共产主义的华裔科技巨头天然不信任,国会议员一定会迎合这个民意市场。
脱钩剧本 · 被动而非主动
「公开支持台独 + 批共」作为标志性事件这个剧本概率较低;更可能的路径是被动出局。
Jensen 的本能是商人式回避 — 2024 年说 Taiwan 是 country 后第二天就主动澄清「不是地缘政治表态」、息事宁人 — 而不是政治站队。所以脱钩更可能的剧本是:
- 美国国会推更严的出口管制 — H20 之后下一代继续被卡;Sovereign AI 法案落地
- CFIUS 介入对 NVIDIA 的中国合作 / 客户结构
- 董事会受压调整 China-related 业务披露;启动战略评估
- 最终被迫退出中国市场 — 25% 数据中心营收口径直接归零
- 结果差不多但姿态会很不一样 — 不是英雄式分手,是合规推力。
所以英伟达在政治上一定会先于苹果 / 特斯拉被处理掉。这是独立于挑战者结构的第二条加速曲线。
§05 · 时间与信号 — when & how to watch

图片:Wikimedia Commons / 2017 · CC BY-SA 4.0。
这是整段分析里最容易判断错的地方。英伟达的衰落几乎确定,但「几乎确定」和「明年开始」之间还有很长的路。供应链锁死(HBM、CoWoS、ODM 整柜产能预订到几年后)+ 训练侧软件惯性 + 大客户不愿一次性切换,这三层缓冲很厚。空头的难点不是方向,是时机。
蛋糕在变大:四大云厂商 2026 年合计资本开支接近 $600B;高盛预计 2025–2027 总开支 $1.15T。即便挑战者全部到位,2028 年 NVIDIA AI 数据中心市占大概率仍在 60% 以上 — 份额下降但绝对收入仍可能增长。
三阶段节奏
- 阶段一 · 2026–2027 · 表面上还在赢。 整体收入仍增长,毛利率守在 70–75%。云厂商自研 ASIC 取得 10–15% 份额,但训练市场扩张抵消推理下降。表面看英伟达毫发无伤 — 这是最容易被忽悠的阶段。
- 阶段二 · 2027–2028 · 真正的拐点窗口。 推理市场绝对规模超过训练,推理流失的金额开始压过训练增长,整体份额明显下降,毛利率向 65–70% 下移。这是真正的拐点窗口 — 非 GAAP 毛利率跌破 70% 是结构性信号。
- 阶段三 · 2028 之后 · 堡垒动摇。 谷歌 TPU、AMD MI 系列、可能的 OpenAI 自研芯片在训练侧实质性破墙;如果「模型烧进硬件」路线跑通,整个推理硬件市场被重新洗牌,毛利率向 60% 以下回归。GPU 从「分配品」变回「商品」。
非 GAAP 毛利率 · 三阶段轨迹
参考:2022 年游戏 GPU 周期毛利率从 64% 跌到 56%(用了一年) — 周期性供需逆转的下跌速度参考值。结构性拐点会更慢但更难恢复。真正的警报是非 GAAP 毛利率跌破 70% 后无法修复。
主要警报 · 跟踪非 GAAP 毛利率三档阈值
- 一级警报 · 毛利率 < 70% · 挑战者已实质性议价。 这是结构性信号,不是周期波动。意味着大客户已经在拿替代方案谈价,Blackwell Ultra 的 35% 加价模式难以延续。
- 二级警报 · 毛利率 < 65% · 进入定价权丧失螺旋。 规模效应也救不回来。Q-on-Q 连续下降 2–3 个季度即确认。
- 三级警报 · B 系列 / Rubin 降价清库存 · GPU 已变回商品。 从「分配品」变回「商品」。一旦出现降价清库存,意味着结构性供需逆转完成。
辅助信号
- 头部云厂商自研 ASIC 占比。 Capex 中「自研 ASIC 占比」是否突破 25%。当前 Google + Amazon 合计 ~15%,需要观察 2027 H2 数据。
- 推理产品线定价压力。 B200 NVL 这种推理优化版本的定价压力,会比训练旗舰更早松动。
- 模型厂自研 / 采购非 GPU 推理硬件实际出货。 OpenAI-Cerebras $20B 这种交易要看实际交付不是公告;OpenAI 自研芯片(博通合作)的流片节奏是关键节点。
- Cerebras IPO 后估值表现。 市场对替代路径的定价。如果 IPO 后估值能维持 $30B+,意味着公开市场认可挑战者叙事;如果跌破 $15B,意味着市场仍信 NVIDIA 垄断。
- 中国市场实际营收规模。 地缘政治进展的滞后指标。如果出口管制再升级、营收占比从 25% 降到 5% 以下 — 是政治剧本兑现的标志。
- Sovereign AI 类法案。 美国国会层面任何要求「敏感算力出货前置审查」的立法,都是政治剧本提前的信号。
§06 · 综合判断 — the inflection signal

图片:Wikimedia Commons / CC BY-SA 4.0。
整段逻辑是闭合的。
六条结构性观察
- 架构收敛释放硬件设计自由度。 Transformer 是新的 x86;CUDA 没被攻破而是被绕开。
- 挑战者格局已成形。 大厂 ASIC + 一线初创 + 中国国产替代 + 模型厂烧硬件,2026 全球初创已融 $8.3B。
- 训练堡垒坚固但推理软肋暴露。 2025 是分水岭,2029 训推 1:4。每一条推理工作负载特征都对 NVIDIA 不利。
- 模型厂可能跨入硬件层。 OpenAI 投 Cerebras $20B + 博通自研推理芯片 + Taalas 烧硬件路线 — 整个 AI 价值链可能被重新切分。
- 政治风险加速这个过程。 NVDA 与 AAPL / TSLA 的中国敞口本质不同 — 「卖战略物资」vs「贡献供应链」;Jensen 华裔背景 + 反复表态被质疑「过度功利」,在美国国会民意市场逻辑上一定先于苹果 / 特斯拉被处理。
- 时间窗口比直觉长。 HBM / CoWoS / ODM 锁死 + 训练软件惯性 + 大客户不愿一次性切换,这三层缓冲很厚。空头的难点不是方向是时机。
底线观察
主导地位仍在,而且依然强势。但护城河之外,挑战者已经从「追赶」转向「绕开」。
真正要紧盯的不是「谁追上来了」,而是「英伟达自身的拐点信号有没有出现」 — 非 GAAP 毛利率,就是那个拐点信号。
跟踪节奏:
- 毛利率 75% → 70%(一级警报)
- 毛利率 70% → 65%(二级警报)
- B / Rubin 降价清库存(三级警报)
- 云厂商自研 ASIC 占比突破 25%
- OpenAI-Cerebras $20B 实际交付
- Sovereign AI / 出口管制升级
毛利率不破 70%,垄断结构还稳;一旦破 70% 且无法修复,就是拐点信号被触发的瞬间。
Apple 在 AI 时代真正的优势不是「我也能做模型」,是「我不需要做模型」(见 /zh/signals/apple-ai)。NVIDIA 真正的危险不是「有人在追」,是「不能慢下来」 — B 端客户的理性会反向加速整个过程。这两条是同一个结构性观察的两面。
— 反共识研究 · 2026-04-26